Small project Makefile
12, Aug, 2015Too much coding time is setting stuff up rather than making things. I use IDEOne a lot for snippets of code. Sometimes I even brave Javascript for the convenience of having a file that can run on any computer with a web browser.
But there are times when you have to bite the bullet and split something into several files. This usually means setting up a project file in an IDE, after installing 8 gig of updates. Bah!
Here’s a Makefile I wrote to get projects up and running quickly. It takes a folder of code and makes an executable. Nothing fancy, but it does the job. Works on Linux and Mac OS X (Get the Command Line Tools if you don’t want XCode).
APPLICATION= App.exe CPP= g++ CPPFLAGS=-Wall -Werror -pedantic BUILD_DIR= ../Build SOURCE_DIR= ../Source SOURCES=$(shell find $(SOURCE_DIR) -name *.cpp | tr '' '/') CLASSES=$(SOURCES:$(SOURCE_DIR)%.cpp=$(BUILD_DIR)%.o) all: $(APPLICATION) $(APPLICATION): $(CLASSES) $(CPP) $(CLASSES) -o $(BUILD_DIR)/$(APPLICATION) $(BUILD_DIR)/%.o: $(SOURCE_DIR)/%.cpp $(CPP) $(CPPFLAGS) -c $< -o $@ clean: @rm -r $(BUILD_DIR)/*
Halton sequence
11, Jul, 2015Following on from the Blum Blum Shub post, there are times when you want a set of positions that look random, but which are spread out more evenly than a random plot would give. If you remember, we used BBS to plot this:
# # # # # ## # # # # # # # # # # # # # # # # # # # ## # # # # # # # # # # # # # # # # # # ## # # # # # # # # # # ## # # # ## # # # # # # # # # # # # # ## # # # # # # # ## # # # ## #
Whereas Halton sequences will give you something like this:
# # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # #
This works by following a simple but different patterns on each axis. The pattern is called a Van der Corput sequence, and here’s what it looks like in base 2:
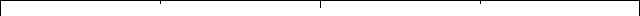

The sequence is generated by “flipping” the index over the decimal point. For example, 12345 becomes 0.54321 or in binary, 110 becomes 0.011.
This is really simple to do in code. This will give you the above output (View on IDEOne):
#include <stdio.h>
#include <stdint.h>
#include <math.h>
float VanDerCorput(uint32_t index, uint32_t base)
{
float result = 0;
float f = 1.0f;
uint32_t i = index;
while (i > 0)
{
f /= static_cast<float>(base);
result += f * (i % base);
i /= base;
}
return result;
}
int main()
{
uint32_t Bitmap[32] = {0};
for (int i=0 ; i<100 ; ++i)
{
uint32_t x = (uint32_t) floorf(VanDerCorput(i, 2) * 32);
uint32_t y = (uint32_t) floorf(VanDerCorput(i, 3) * 32);
Bitmap[x] |= 1<<y;
}
for (uint32_t y=0 ; y<32 ; ++y)
{
for (uint32_t x=0 ; x<32 ; ++x)
{
printf("%c", Bitmap[x] & 1<<y ? '#' : ' ');
}
printf("\\n");
}
return 0;
}
Blum Blum Shub
10, Jul, 2015Blum Blum Shub is a pseudo random number generator which has been proven to be secure when used appropriately. We’re not going to use it appropriately here.
What we are going to do is exploit the fact that you can compute any number in the sequence directly, which makes it suitable for procedural content generation. A hashing algorithm would probably be quicker, but BBS makes it easier to generate a long list of values without any repetition. Nobody wants two planets called Arse.
The formula for generating values sequentially is:
M is the product of two large primes (P * Q), where P mod 4 = 3, and Q mod 4 = 3. Here we will use a value of M which is representable in 32 bits, which is where cryptographers in the audience will start wincing. The reason for using a 32 bit value is that the square will fit in a 64 bit integer, and we don’t need to use a big number library.
The original paper recommends using special primes to produce a large cycle length, where P = 2 * P1 + 1, and P1 = 2 * P2 + 1. As I had a limited number of primes of an appropriate magnitude, I simply let the computer churn away at possible combinations. Within a couple of minutes it spat out 64007 and 66959, which give a cycle length of 535681477. Here, 64007 is a special prime but 66959 is not. Interestingly, I did not check for P and Q being equal, and a little while later it found that using 64007 for both gives an even longer cycle length (1024160005). This doesn’t fit the BBS criteria for P and Q to be distinct, but hey, it works!
The seed value (X0) isn’t too important, but an odd prime that isn’t P or Q usually works well. Computing a value directly uses Euler’s theorem:
Where λ(M) is the lowest common multiple of (P-1) and (Q-1). Here’s some code:
#include <stdio.h>
#include <stdint.h> // For uint32_t / uint64_t
#include <algorithm> // For std::swap
uint32_t GreatestCommonDenominator(uint32_t x, uint32_t y)
{
if (x < y)
std::swap(x, y);
while (y > 0)
{
x = x % y;
std::swap(x, y);
}
return x;
}
uint32_t APowBModC(uint32_t a, uint32_t b, uint32_t c)
{
if (b == 0)
return 1;
if (b == 1)
return a % c;
uint32_t b1 = b >> 1;
uint32_t b2 = b - b1;
uint64_t a_pow_b1_mod_c = APowBModC(a, b1, c);
uint64_t a_pow_b2_mod_c;
if (b1 == b2)
{
a_pow_b2_mod_c = a_pow_b1_mod_c;
}
else
{
a_pow_b2_mod_c = APowBModC(a, b2, c);
}
// a^b1 * a^b2 == a^(b1+b2)
uint64_t result = (a_pow_b1_mod_c * a_pow_b2_mod_c) % c;
return static_cast<uint32_t>(result);
}
class BlumBlumShub
{
uint32_t P, Q, M, Seed, Value;
public:
BlumBlumShub(uint32_t p, uint32_t q, uint32_t s)
{
P = p;
Q = q;
Seed = s;
M = p*q;
Value = s;
}
uint32_t NextInt()
{
uint64_t value64 = static_cast<uint64_t>(Value);
Value = (value64*value64) % M;
return Value;
}
uint32_t GetInt(uint32_t index)
{
uint32_t gcd = GreatestCommonDenominator(P - 1, Q - 1);
uint32_t lcm = (P - 1)*(Q - 1) / gcd;
uint32_t temp = APowBModC(2, index, lcm);
return APowBModC(Seed, temp, M);
}
uint32_t RandMax() const
{
return M - 1;
}
};
int main()
{
BlumBlumShub bbs(64007, 66959, 48023);
for (uint32_t i = 1; i <= 100; ++i)
{
printf("%u t %un", bbs.NextInt(), bbs.GetInt(i));
}
uint32_t Bitmap[32] = { 0 };
for (uint32_t i = 0; i<100; ++i)
{
uint32_t x = bbs.NextInt() % 32;
uint32_t y = bbs.NextInt() % 32;
Bitmap[x] |= 1 << y;
}
for (uint32_t y = 0; y<32; ++y)
{
for (uint32_t x = 0; x<32; ++x)
{
printf("%c", Bitmap[x] & 1 << y ? '#' : ' ');
}
printf("n");
}
return 0;
}
Which will output the first 100 numbers calculated sequentially and directly, then a 32 x 32 grid with 100 random positions plotted.
# # # # # ## # # # # # # # # # # # # # # # # # # # ## # # # # # # # # # # # # # # # # # # ## # # # # # # # # # # ## # # # ## # # # # # # # # # # # # # ## # # # # # # # ## # # # ## #
References
A Simple Unpredictable Pseudo-Random Number Generator (Blum Blum Shub, 1986)
Compile Time Hashing
1, Jul, 2015Compile time string hashing has been done to death since the AltDevBlogADay article and the Humus post. I couldn’t find an implementation that didn’t make it look far more complicated than it really is, so here’s my take:
#include <stdio.h>
typedef unsigned int u32;
//
// Template version, evaluated at compile time in optimised builds
//
template <u32 N>
constexpr u32 HashFNVConst(const char(&text)[N])
{
return (HashFNVConst<N-1>((const char(&)[N - 1])text) ^ static_cast<u32>(text[N - 2])) * 16777619u;
}
template<>
constexpr u32 HashFNVConst<1>(const char(&text)[1])
{
return 2166136261u;
}
//
// Loop version, evaluated at runtime
//
u32 HashFNV(const char* text)
{
u32 hash = 2166136261u;
for (const char* c=text ; *c ; ++c)
{
hash = hash ^ static_cast<u32>(*c);
hash *= 16777619u;
}
return hash;
}
int main()
{
const char * text = "Hello";
printf("0x%x (Loop version)\\n", HashFNV(text));
printf("0x%x (Template version)\\n", HashFNVConst("Hello"));
return 0;
}
This is a FNV1a hash. It uses constexpr so requires a C++11 compliant compiler (VS2015 or recent GCC / Clang). Here’s the obligatory disassembly:
printf("0x%x (Template version)n", HashFNVConst("Hello"));
0102106F push 0F55C314Bh <--- The hash
01021074 push 1022128h
01021079 call printf (01021010h)
Pronounce
9, Apr, 2015Pronounce is a tiny rule based grapheme to phoneme (G2P) converter.
It achieves roughly 75% syllable accuracy on CMU pronouncing dictionary data. This is far lower than state of the art systems, but it has the advantage of being much smaller and simpler. In fact, the conversion takes place in a single self-contained function.
I wrote this for situations like sentiment analysis, or a speech input system where the user chooses from a list of options. These cases require less accuracy than a full speech to text system.
Metascore per hour
30, Jan, 2015I am sorry. I made a Bad Thing.
Specifically, a web page that ranks the games in your Steam library by their Metascore, divided by the time it takes to complete them. You can try it by entering your steam username here:
Please don’t take this to mean that I approve of Metascore, although at times it can be incredibly insightful.
The page was inspired by Steam Left, and was made possible by the Steam Web API and the How Long To Beat database. It was written largely to annoy Dan.
Oct encoding
21, Jan, 2015Oct encoding compresses a 3D unit vector into 2 values. This is particularly handy for deferred rendering, where you want to pack a normal into a slim G buffer, or for storing a normal map in a BC5 texture. The technique involves projecting the vector onto a octahedron, then unfolding it into a square.
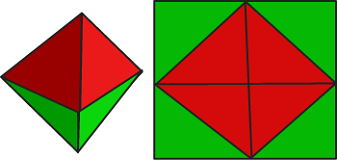
I’ve made a visual testbed to compare the technique and a couple of alternatives (such as Spheremapping) at different precisions.
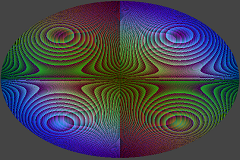
There’s a detailed explanation in A Survey of Efficient Representations for Independent Unit Vectors. Crytek best fit normals offer better precision but require a texture lookup. c0de517e has some interesting ideas about blendable, wrappable encodings.
Introducing Shader Shed
19, Nov, 2014Shader Shed is a portable web based shader IDE featuring:
- Single simple HTML file.
- Portable. No need for a web server or any complicated setup.
- Supports most Shader Toy shaders out of the box.
- Built in, base64 encoded textures (avoids cross domain security warnings).
- Public domain license.
- Share shaders with URL encoding (see below).


Or click here to start a new project.



